

数据看成一种新兴的坐褥要素,最大的价值在于数据的分享、探望和诳骗。在数据驱动的天下中,企业越来越把稳将其数据滚动为有价值的家具,以便在通盘企业中放肆探望和使用,最终贪图是向数据使用者提供预构建的数据家具,从而更快地大范围分享、探望、诳骗数据,引发数据的潜能。
数据家具如胁制面板、评释、API、数据可视化、机器学习模子等,具有可斟酌的价值况且可重用,旨在提供委果数据来科罚业务问题。这种对可膨大、活泼数据探望的需求催生了数据编织和数据网格等架构方法,以科罚当代数据环境的复杂性,并开释数据钞票的全部后劲。
Data Fabric的中枢价值在于整合数据资源,绵薄数据探望,自动化处理数据,保险安全合规。而Data Mesh则采选散布式数据架构方法,将数据统共权分派给跨职能的边界团队,由这些团队向最终用户提供数据家具。
因此,Data Fabric和Data Mesh正成为企业为当下和畴昔选拔数据架构的两种主要选拔,亦然构建数据空间,终了数据价值的病笃旅途。
Data Fabric:以数据为中心的企业的“必备”架构
Gartner将“数据编织Data Fabric”列为“2021年十大数据和分析时期趋势”之一,并预测到2024年,25%的数据照顾供应商将为数据编织提供完满的框架。
另一家市集辩论公司Forrester臆想,刻下有20%的组织采选了多个云,预测这一数字将在畴昔三年内翻一番,也为Data Fabric科罚决议提供商带来了契机。Data Fabric在现在的多云和搀和云行业中默契着病笃作用。
为什么要发展Data Fabric?从应用上看,跟着数字化发展,企业数据源加多,数据量捏续增长,数据与应用孤岛多数通晓。
企业的业务数据花式已从以结构化为主,转变为多种类型并存,像结构化、半结构化、非结构化数据共存,对及时或事件驱动的数据分享需求也在攀升。
同期,企业上云趋势下,在搀和数据环境中跨平台、跨环境进行数据的汇集、探望、照顾和分享变得极为不毛,要从分散且高度关联的数据获取可实践洞见,挑战巨大。
这些数据照顾难题亟待科罚,企业急需唐突数据钞票万般化、散布式、范围纷乱和复杂等问题。
从时期上看,多年来,为撑捏数据分析出现了许多种架构。最流行的是企业信息工场(Corporate Information Factory)和数据仓库总线架构,满足企业在构建企业数据仓库(EDW)时对数据分析的需求。
但跟着时期和期间的跨越,数据科学界所需的分析和对及时数据进行的及时流分析仅靠企业数据仓库环境根柢无法撑捏。
于是数据编织Data Fabric应时而生,Forrester分析师Noel Yuhanna于2013年界说Data Fabric。从主见上讲,Data Fabric大数据结构本质上是一种元数据驱动的面貌,用于联结不同的数据器具围聚,以有凝华力的自助作事面貌科罚大数据技俩中的要道痛点。
看成新兴的数据照顾和处理方法,Gartner将Data Fabric界说为包含数据和联结的集成层,通过对现存的、可发现和可推断的元数据钞票进行捏续分析,来撑捏数据系统跨平台的遐想、部署和使用,从而终了活泼的数据委用
正如Gartner所说,Data Fabric是一种跨平台的数据整合面貌,能集成统共业务用户信息,具有活泼弹性上风,让东谈主们可随时获取数据,还能大幅镌汰集成遐想、部署和善良的时间。Data Fabric数据编织的贪图是创建一个可以涵盖统共局势的分析和数据架构,可以用于任何类型的分析,并让统共需要的东谈主齐能无缝的探望和分享。
Gartner界说的Data Fabric智商架构如下:

怎样意会Data Fabric呢?Data Fabric是一种端到端的融合架构,它将组织所需的主要数据和分析器具整合在一齐。诳骗AI和机器学习等时期,通过高档功能得到增强,以自动化和优化数据照顾经过,从而在您的系统和平台上创建融合、一致和集成的数据环境。这种融合的架构通过自动化元数据照顾和AI驱动的洞悉动态生成数据家具,从而灵验地摒除孤岛并培养敏捷性。
起源,Data Fabric是一种数据架构想想,并非特定器具集,旨在以融合方法照顾异构数据器具链,把委果数据从各干统共据源,以活泼且易被业务意会的面貌提供给统共干统共据豪侈者,创造比传统数据照顾更多价值。
可将Data Fabric瞎想成一张捏造网,网上的节点是IT系统或数据源,就像大脑神经元联结传递信息相同,是一种捏造联结,能让数据赶快流动并融合提供作事。
其次,Data Fabric科罚决议提供数据探望、发现、休养、集成、安全、治理、复古和编排等边界的功能。
第三,Data Fabric和数据集成不同。数据集成侧重于交融异构存储数据,构建融合视图,包含数据同一、休养、清洗等操作,专注于数据的复制和移动,如ETL加工等。而Data Fabric是架构想想,数据捏造化是其要道时期之一,数据捏造化可在不移动数据情况下从泉源探望数据,具备跨平台敏捷集成等功能。
另外,数据湖仅仅Data Fabric的异构数据源之一,数据编织通过融合框架撑捏散布式环境中的数据豪侈。
终末,全面整合后的数据分析架构有好多自制,如:让数据照顾更放肆,让数据更安全、更可靠、更一致;让数据和分析钞票民主;造谣了复杂性,促成了协同的、纪录在案的数据血统和数据使用经过等。
数据编织Data Fabric是怎样终了的?要达到数据编织的方针,需要具备以下五个智商:
其一,数据源联结智商。数据编织概况联结丰富万般的数据源,像企业里面的数据库、数据仓库、数据湖、BI、应用系统等,也包括非结构化数据源如物联网传感器等,还能从外部大众数据获取数据。
其二,活泼数据目次智商。它能自动识别获取元数据,借助ML/AI分析数据语义打标签加深业务意会,进而构建常识图谱,将碎屑化元数据有序组织,便于东谈主机意会和数据处理,为搜索、挖掘、分析助力。
其三,基于常识图谱的智能遐想与推选智商。常识图谱可加速数据集成遐想,终了快速检索自动填充,还能进行智能推选,把合适的数据在合当令间发送到合适的东谈主。
其四,动态集成与自动编排智商。基于前边的基础可终了动态集成,采选履行和网格时期,同期数据自动化编排可简化优化集成经过。
其五,面向豪侈者的自助智商。能为各种数据用户提供作事,满足专科IT用户复杂需乞降业务东谈主员自助式数据处理需求。
Data Fabric的重心供应商。市集辩论公司对Data Fabric企业有详备的分析。
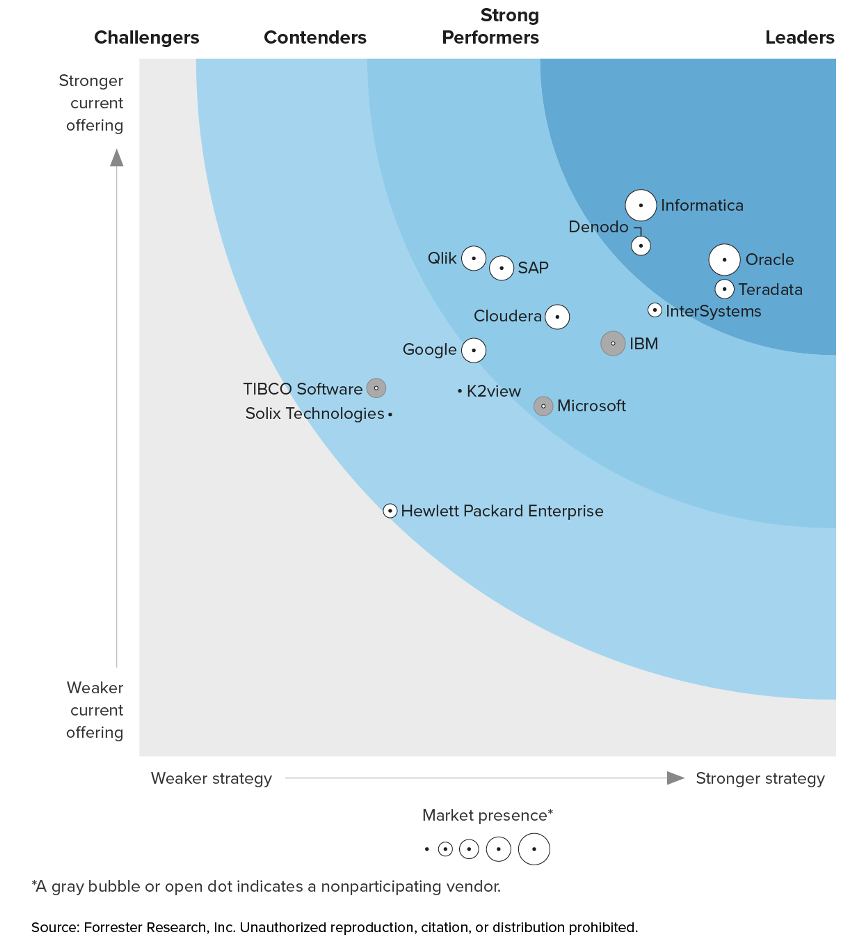
Forrester将Denodo、Informatica、Oracle等评为Enterprise Data Fabric边界的指点者。在评释中,Denodo在“数据探望、委用和数据家具”尺度中得回高分,在“部署和照顾”以及“数据处理和事务”尺度中得回高分之一。Denodo还在Roadmap和Partner Ecosystem尺度中得回了高分。
确认该评释,Denodo尽头得当专注于企业范围数据结构计策的客户,以撑捏及时刻析、客户360度、数据工程、数据科学、物联网分析、运营洞悉和预测分析用例等。
刻下,一些器具供应商(包括Informatica和Talend)提供包含上述许多功能的Data Fabric,而其他器具供应商(如Ataccama)则提供Data Fabric的特定部分。
Google Cloud通过其新的Dataplex家具撑捏Data Fabric方法。Data Fabric中各个组件之间的集成频繁通过API和通用JSON数据花式进行处理。
Data Mesh:克服湖仓痛点,让数据跨组织应用
在领有了Data Fabric之后,为什么还要推出Data Mesh?
数据仓库旨在存储数据分析师用于回溯SQL分析的大部分结构化数据,由分析师用于恢复联系结构化数据的业务问题;数据湖主要存储数据科学家用于构建预测性机器学习模子的大部分非结构化数据。
而以及时数据流和对云作事的接受为象征的新一代系统,并莫得科罚数据仓库和数据湖之间潜在的可用性差距。
许多组织构建和善良悉心遐想的ETL数据管谈,以试图保捏数据同步,也推动了对“高度专科化数据工程师”的需求。可是数据休养不成由工程师硬连线到数据中,而应该是一种过滤器,应用于统共用户齐可以使用的一组通用数据。
因此,数据约莫以原始局势保留,况且一系列特定于边界的团队在将数据塑形成家具时禁受这些数据,而不是构建一组复杂的ETL管谈,将数据移动和休养到挑升的存储库中,以便各个边界对其进行分析。
散布式数据网格Data Mesh即是通过一种新架构来科罚这一问题。

Data Mesh让数据使用者可以不再是数据的旁不雅者,而是在数据功能的遐想、开荒和照顾中默契作用。
散布式数据网格Data Mesh是Zhamak Dehghani于2019年在接头公司Thoughtworks使命时创造的,旨在匡助科罚传统蚁合式架构(如数据仓库和数据湖)中的一些基本谬误。
Data Mesh是一种用于分析和数据科学的去中心化数据照顾架构。传统的数据架构频繁蚁合数据,导致可膨大性、活泼性和治理方面的挑战。Data Mesh 建议了一种去中心化的方法,将数据视为家具,并由组织内的去中心化团队或边界(如营销、销售和客户作事)进行照顾。
当年,蚁合式基础设施团队将照顾跨域的数据统共权。可是,Data Mesh模子将这种统共权转机给坐褥者,可以在遐想API时计划到主要数据使用者的利益。
除了认真对数据进行编目、缔造使用和权限策略以及界说语义除外,这种域驱动的方法还善良一个蚁合式数据治理团队,以实施围绕数据的尺度和实践。
Forrester合计,Data Mesh让数据使用者可以不再是数据的旁不雅者,而是在数据功能的遐想、开荒和照顾中默契积极作用。
为此,建议了Data Mesh框架的四个原则,即用于凹凸文、意会和职守的域统共权,用于环境信任和胁制的蚁总算计数据治理(FCDG),通过自助作事膨大数据使用和业务价值,数据即家具,用于分派和照顾数据功能的买卖价值。
Forrester也建议,有五个成分会影响Data Mesh在当代数据基础设施中的应用,即语义学、界说和开荒数据家具、投资组合照顾即数据家具照顾、DataOps的作用,以及与苍劲的主题大众蚁合。
Data Mesh是数据架构中的一个新兴主见,它为企业提供了多项自制。
去中心化的数据统共权。通过在特定边界的团队之间分派数据统共权,Data Mesh有助于民主化、摒除瓶颈并使团队概况作念出联系其数据的决策,加速革命速率,更好地与业务贪图保捏一致。
转变了数据探望和可膨大性。Data Mesh通过增强数据探望、安全性和可膨大性来改善使用数据的团队的体验和成果。其贪图是通过在数据统共者、坐褥者和使用者之间缔造平直联结,晋升业务用户对数据的可探望性和可用性。
故意于晋升数据质料和鼓舞数据治理。蚁合式架构可能难以善良数据质料和实施治理尺度,因为这些职责频繁蚁合在数据团队中。Data Mesh 饱读吹特定边界的团队领有其数据的统共权,从而晋升数据质料并适合治理尺度。
故意于摒除数据孤岛和不安谧收复。Data Mesh的一个显赫上风在于它概况减少数据孤岛。通过部署自助式数据基础架构,可以放肆地跨域探望数据,从而促进合作并加速数据发现的门径。
便于进行东谈主工智能和机器学习。Data Mesh架构中的数据分散化故意于部署AI 和ML选项,依赖于平凡而万般的数据集来高效运转。通过更放肆地探望数据和资源,团队可以更快地迭代AI和ML实验和原型,有助于优化模子并跟着时间的推移晋升其性能。
稠密企业推出了Data Mesh买卖化科罚决议。
2024年第3季度的Forrester Wave评估了12家企业“企业数据目次”的决议,Atlan被评为指点者。企业数据目次也曾成为Data Mesh结构落地的一种买卖化家具。
跟着组织寻求概况弥合复杂数据集、治理、业务洞悉和AI撑捏之间差距的科罚决议,数据目次、数据质料器具和数据治意会决决议正在交融。在一个拥堵、弥远的市集中,Atlan通过为统共业务和时期变装提供“自动化AI/ML元数据、GenAI 援救发现、端到端复古、及时处理和肖似 Netflix 的个性化体验”而被评为指点者。它提供凹凸文感知的关系映射、复杂的使命经过、第三方应用要领小部件、动态探望胁制和逐日节录,使用户概况了解和胁制数据生态系统。
Snowflake Data Mesh使组织概况从整局势架构过渡到分散、可膨大的数据生态系统。它诳骗Snowflake的云原生平台来终了域驱动的统共权、无缝数据集成和蚁合治理。
Snowflake Data Cloud即是这么一个平台。Snowflake的多集群分享数据架构整合了数据仓库、数据集市和数据湖,使其成为缔造自助式数据网格平台的一个可以的选拔。
2023年,Ascend.io在公司的Data Pipeline自动化平台中集成新的Data Mesh功能,使企业初度概况从单个胁制台跨多个数据云分享和承接数据。
Ascend平台中整合的全新Data Mesh功能是通过结合Ascend独到的两项时期而开荒的:可膨大架构可在融合架构上撑捏多个云数据平台即Snowflake、Databricks、BigQuery和开源Spark);Ascend的指纹识别时期内置于DataAware Control Plane中,使公司概况将代码和数据承接在一齐,追踪复古并确保数据完满性。通过将这两项功能相结合,公司可以在通盘数据生命周期中跨数据平台传输时全面追踪、自动化和优化数据。
Starburs公司开荒了名为Trino的散布式SQL查询引擎Presto版块。Starburst将 Trino(当年称为PrestoSQL)定位为“Data Mesh的分析引擎”,可以对存储在一系列数据库和文献系统中的数据实践SQL查询。它领先遐想为在Facebook修改后的Hadoop集群中运转,但如今最大的用例是查询存储在S3或S3兼容对象存储系统中的数据,以及Databricks的Delta Lake等湖仓一体。
Apiphani推出了一套新的作事Apiphani Data Pipeline,专注于匡助客户构建一个推动高成果、可靠性和价值的Data Mesh科罚决议,为客户最病笃的买卖智能、机器学习、东谈主工智能和数字家具奠定了基础。
Apiphani Data Pipeline包含当代数据和分析平台所需的统共组件,包括云原生器具和数据目次科罚决议。除了中枢时期平台除外,Apiphani Data Pipeline 还围绕托管作事构建,允许客户盘算推算、实施和善良生成的数据管谈,产生可靠、简化的自助式数据,为最终用户、数据专科东谈主员、工程师、业务司理和高管带来价值。
Data Fabric Vs. Data Mesh:使用正确的架构进行数据照顾
正如咱们所看到的,Data Fabric与Data Mesh之间存在相似之处,但也有一些各异。
Data Mesh是一种高度分散的数据架构,旨在唐突包括穷乏数据统共权、穷乏高质料数据和膨大瓶颈在内的挑战。Data Mesh的贪图是将数据视为一种家具,每个来源齐有一个数据家具统共者,可以成为跨职能数据工程师团队的一部分,克服了传统数据湖和数据仓库的问题。
Data Fabric是一个联结数据和分析经过的一体化集成的架构层。它诳骗现存的元数据钞票来撑捏跨统共环境和平台的遐想、部署和正确使用数据。Data Fabric旨在通过自动化经过加速数据推理并提供及时见地。它将数据、分析和姿色板集成,并用作管意会决决议,允许在散布式环境中进行探望。
方法各异:自动化与东谈主工包容。Data Mesh从以东谈主员和经过为中心的角度处理数据,并将数据视为家具。
Data Fabric诳骗东谈主工和机器功能当场探望数据或在适那时撑捏其整合。它将联结数据源、类型和位置的时期与探望数据的不同方法相结合。Data Fabric捏续识别、联结和丰富来自不同应用的及时数据,以发现数据点之间的关系,通过构建一个图表来存储算法可用于业务分析的互连数据形色来终了这少量。
数据存储各异:蚁合式与分散式。在Data Mesh中,数据分散存储在公司里面的域中。每个节点齐有腹地存储和算计智商,况且不需要单点胁制即可运转。从本质上讲,原始数据保留在域中,并为特定使用案例生成数据集副本。
在Data Fabric中,数据探望通过高速作事器集群进行蚁合,以终了Data Fabric中的蚁合和高性能资源分享。
构建面貌的各异。Data Mesh旨在取代数据湖成为数据和分析边界主导架构,引入了零丁于特定时期的组织视角。其架构罢职边界驱动的遐想和家具想维,以克服与数据干系的挑战。Data Mesh数据网格文化是对于联结东谈主们并创建蚁合职责结构。
Data Fabric诳骗元数据来推动推选,而Data Mesh则与主题大众合作来监督域。这些域是可零丁部署的微作事集群,用于与用户通讯。它由代码、使命流、团队和时期环境构成。
Data Fabric与时期、业务和运营数据配合使用,况且主要与时期、业务和运营数据兼容。可视化器具使时期基础设施易于讲解,并匡助组织照顾其存储资本、性能、安全性和成果。此外,公司可以在万般数据存储库上捏造部署单一Data Fabric,以照顾不同的数据源和下贱使用者。

数据探望各异:API与受控数据集。在Data Mesh中,数据通过受控数据集提供。起源,将信息从部门数据存储复制到分享位置。在Data Fabric中,数据通过基于贪图的API提供。数据被复制到特定使用案例的特定数据蚁合,况且领少见据的业务单元处于胁制之中。
使用案例各异。Data Mesh是搀和云蚁合的瞎想选拔。Data Fabric撑捏单点数据探望,科罚数据质料和存储问题,并处理安全挟制。

理智选拔源于数据熟悉度
Data Mesh和 Data Fabric是当代数据架构范式,旨在科罚在复杂的散布式环境中照顾数据的挑战。天然它们有一些相似之处,也具有格外的特征,使它们适用于不同的用例,以致可以组合使用。
Data Fabric 和Data Mesh两个数据架构主见齐是互补的,可以并存。组织可以在不同的用例中诳骗这两种方法。
确认微软的数据和AI科罚决议架构师James Serra的说法,这两个主见的远离在于用户怎样探望数据。Data Fabric 和 Data Mesh提供了跨多种时期和平台探望数据的架构。但Data Fabric以时期为中心,而Data Mesh则侧重于组织变革。Data Mesh更多地与东谈主员和经过联系,而不是架构;而Data Fabric是一种架构方法,它以一种智能的面貌处理数据和元数据的复杂性,况且可以很好地协同使命。
IBM网站著述高慢,Data Fabric和数据网格Data Mesh可以共存。事实上,Data Fabric可以通过三种面貌终了Data Mesh:
□ 为数据统共者提供数据家具创立功能,如对数据钞票进行编目、将钞票休养为家具以及罢职蚁合治理策略;
□ 使数据统共者和数据使用者概况以万般面貌使用数据家具,如将数据家具发布到目次、搜索和查找数据家具,以及诳骗数据捏造化或使用API查询或可视化数据家具;
□ 诳骗来自Data Fabric元数据的洞悉,通过在数据家具创建过程或监控数据家具过程中从模式中学习来自动实践任务。
组织的数据熟悉度在很猛进程上影响着哪个框架更合适。对于数据熟悉度相对较高且具少见据驱动型文化的组织,Data Mesh可能是一个可行的选拔。这些组织频繁领有完善的数据治理模子、熟悉的数据管谈以及随时准备对我方的数据钞票认确凿团队。
对于数据治理仍在发展的组织,杰出是不同团队之间可能莫得雅致融合的组织,Data Fabric可能是最好选拔。它允许蚁合治理,同期使组织概况在散布式环境中迟缓膨大其数据架构。Data Fabric也更得当元数据熟悉度较高的组织,因为它专注于从元数据中推动智能。
无论选拔哪种架构,元数据照顾齐是Data Mesh和Data Fabric的要道要素。元数据(如时期、运营或业务元数据)对于终了存效的数据发现、治理和影响分析至关病笃。
Data Mesh和Data Fabric两个架构齐有其优点,但要是莫得苍劲的数据完满性基础和明确的元数据照顾策略,齐可能无法到手。在采选这两种方法之前,组织必须确保领有必要的基础设施、数据文化和治理,以最大胁制地默契其数据的价值。最终贪图是提供委果、可膨大的数据家具,从而提供买卖价值,而领有准确、一致和情境化的数据对于终了信任至关病笃。
文:放飞 / 数据猿
责编:注视深空 / 数据猿


 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP